Visão Computacional - INF2604 / Prof. Marcelo Gattass
Trabalho 2 - Subtração de Fundo
Guilherme Schirmer de Souza
Download da apresentação
1 - Introdução
Subtração de fundo é um método de processamento de imagem cujo objetivo é isolar um objeto ou partes de objetos de uma imagem. Algumas utilizações
clássicas do uso dessa técnica são para detectar invasores em um local (vídeos de segurança) assim como para aplicações de entretenimento e cunho
científico. Hoje em dia, existem várias técnicas destinadas a esse objetivo, sendo algumas com resultados simples e outras com resultados robustos.
O objetivo desse trabalho é apresentar brevemente a teoria de alguns diferentes tipos de técnicas de subtração de fundo, apresentando exemplos de resultados, vantagens e desvantagens.
Além disso, serão apresentados os resultados obtidos com a implementação de uma das técnicas apresentadas, assim como um programa de teste com base na API do OpenCV.
1.1 - O Problema
Conforme descrito anteriormente o problema da subtração de fundo consiste em encontrar em uma determinada cena um objeto, ou conjunto de objetos, que seja de interesse da aplicação.
Embora a idéia seja simples, podem existir vários fatores que complicam esse processo, como movimentação dos objetos de fundo na parte de treinamento,
mudança de iluminação no ambiente, vento, ruído e imprecisão da câmera, etc.
1.2 - Visão Geral da Técnica
A idéia geral das técnicas de subtração de fundo consiste em subtrair uma imagem atual obtida da câmera com uma imagem de referência
(geralmente o fundo obtido no treinamento) usado como base.
Embora a idéia seja simples, se o modelo utilizado para gerar o fundo base não for robusto, muitos problemas ocorrerão no processo de subtração,
conforme mostra a imagem abaixo.

2 - Algoritmos
2.1 - Algoritmos Simples
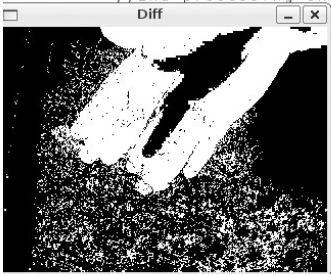
Um dos algoritmos mais simples de subtração de fundo que existe é o de subtração de frames. Baseia-se apenas na subtração de um frame atual por outro
antigo. Se a diferença for maior que um determinado threshold o pixel é considerado como objeto, caso contrário, será considerado fundo. Os resultados
dessa técnica não são nada bons, pois não levam em consideração nenhum embasamento estatístico e nem uma etapa de treinamento. As imagens abaixo
mostram o resultado da diferença de dois frames utilizando essa técnica: pela subtração, a posição antiga da mão é considerada fundo assim como a nova
posição da mão, retornando uma imagem totalmente distorcida da mão.

2.2 - Algoritmos Robustos
Com o decorrer dos anos, vários algoritmos de subtração de fundo foram desenvolvidos, cada um mais robusto (e com suas peculiaridades) que os outros.
Nesse trabalho serão apresentados os seguintes algoritmos (robustos) de subtração de fundo:
- Distorção de Cor e Brilho.
- Ângulo entre os Vetores de Cor
- Construção de Codebooks
Esses 3 algoritmos têm alguns pontos em comum: trabalham no espaço RGB de cor, necessitam de uma etapa de treinamento para modelar o fundo e
têm uma etapa de subtração para detecção dos objetos.
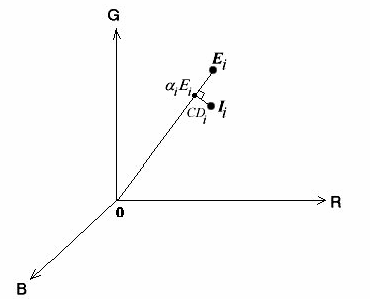
Esse algoritmo baseia-se em um modelo de decomposição da cor na sua parte de cromaticidade e de brilho. Com base nisso, é possível determinar as
diferenças de intensidade luminosa e de croma entre as imagens de referência e o frame analisado e com isso fazer a classificação dos pixels.
Para isso calcula-se a distorção de brilho (escalar que propicia a menor distância entre a cor da imagem de referência com a cor do frame atual) e a
distorção de cor (distância euclidiana da menor distância entre a cor da imagem de referência com a cor do frame atual).
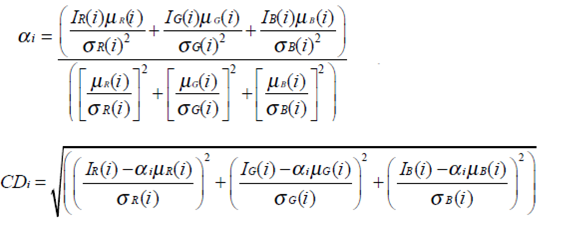
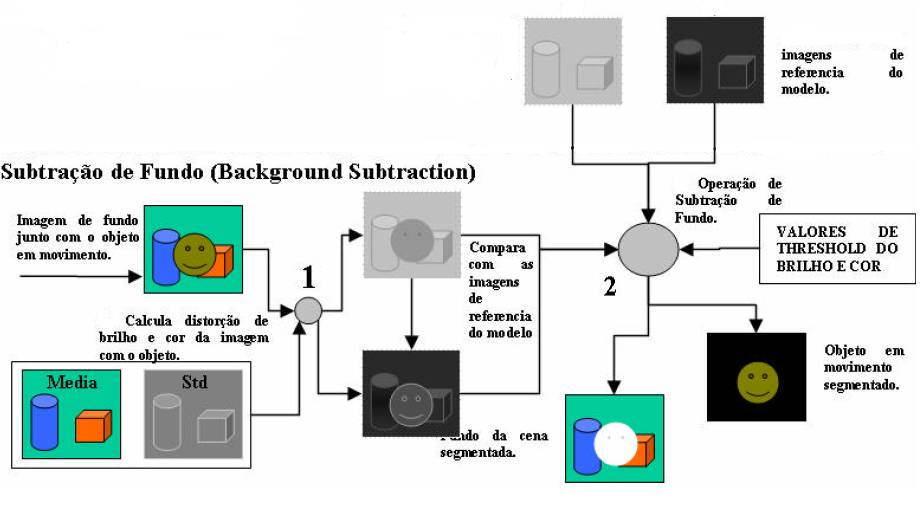
O algoritmo é dividido em duas partes:
A primeira parte é realizada como pré-processamento para gerar um modelo do fundo, o qual é baseado em 4 imagens: média, desvio padrão,
distorção de cor média e distorção de brilho média.
A segunda parte é realizada frame a frame e tem como objetivo classificar os pixels do frame atual e identificar os objetos existentes.
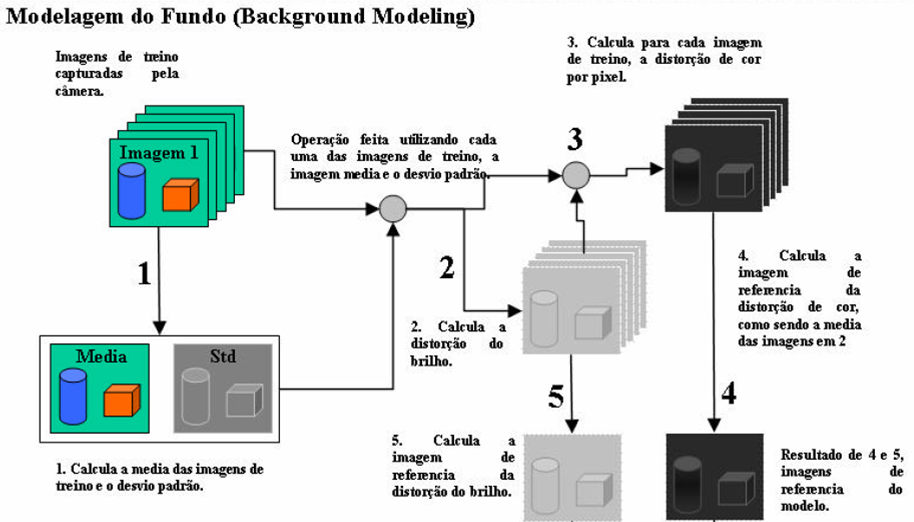
A primeira parte do algoritmo, processo de treinamento, é composto pelas seguintes etapas:
1 - Captura de um número de imagens de treino.
2 - Cálculo de uma imagem média e uma imagem representando o desvio padrão.
3 - Para cada imagem de treino, calcula-se imagens de distorção de brilho e de cor em relação à imagem média.
4 - É gerada uma imagem de distorção de cor e brilho com base na média quadrática das imagens geradas no passo anterior.
5 - No final tem-se 4 imagens de referência: imagem média, imagem do desvio padrão, imagem da distorção de cor e imagem da distorção do brilho.
Essas imagens serão usadas como base para a etapa de subtração do algoritmo.
A imagem abaixo ilustra o processo de treinamento etapa por etapa.
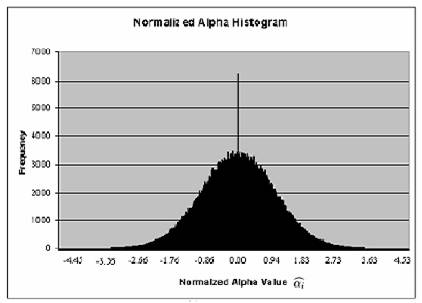
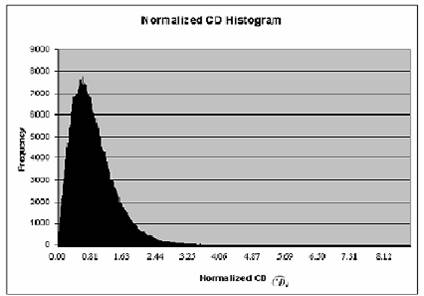
Os limiares são thresholds calculados
com base estatística de forma a obter bons valores para serem usados
no processo de subtração. São obtidos através da montagem dos histogramas de distorção
normalizada do brilho e da cor para todas as imagens de treino com
relação a imagem média e desses histogramas são extraídos tais valores. Para obter esses limiares escolhe-se um determinado percentual de acerto
(como 95%, por exemplo) e obtém do gráfico o limiar que determina tal representação.
- Segmentação - Processo de Subtração
Nessa parte do algoritmo
é feita a subtração do frame atual pela imagem de fundo. Com o
uso das imagens de referências e dos limiares obtidos no processo de treinamento, é possível classificar
os pixels em um dos seguintes grupos:
-Objeto em movimento: se a distorção de cor é maior que o limiar aceito para a imagem de referência.
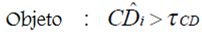
-Fundo original: nos demais casos.
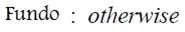
O algoritmo de subtração consiste das seguintes partes:
1 - O frame atual é comparado com as imagens de referência da média e do
desvio padrão para gerar uma imagem de distorção de cor e outra de
brilho.
2 - As imagens geradas são comparadas (subtraídas) com as respectivas
de referência e de acordo com os limiares estabelecidos são
classificadas em fundo ou objeto.
3 - Ao final, é gerada uma imagem apenas com o objeto segmentado.
Abaixo são exibidas algumas imagens como exemplo de resultado do uso da técnica:



2.2.2 Ângulo entre os Vetores de Cor
A idéia principal desse algoritmo é o cálculo do ângulo entre o vetor de cor da imagem média e do frame atual. Dependendo do valor desse ângulo, um pixel é
classificado em fundo ou objeto. Esse algoritmo é dividido em duas partes:
A primeira parte é realizada como pré-processamento para gerar um modelo do fundo, o qual é baseado apenas em uma imagem da média de todas as imagens de
treinamento.
A segunda parte é realizada frame a frame e tem como objetivo classificar os pixels do frame atual e identificar os objetos existentes.
O treinamento é muito simples nesse algoritmo sendo baseado apenas pelos dois passos abaixo:
1 - Captura de um número de imagens de treino.
2 - Cálculo de uma imagem média das imagens de treino para ser usada na etapa de subtração.
- Segmentação - Processo de Subtração
O algoritmo de subtração consiste nas seguintes etapas:
1 - Calcula-se a distância entre o vetor de cor do pixel do frame atual com o pixel equivalente da imagem média de referência.
2 - Se a distância entre os vetores for maior que um limiar superior (threshold), tal pixel é considerado como parte do objeto.
3 - Se a distância for menor que um certo limiar inferior, tal pixel é considerado como parte do fundo.
4 - Se a distância ficar no intervalo entre esses limiares, é calculado o ângulo entre esses vetores. Caso o ângulo seja superior a um determinado limiar
(diferente dos outros dois anteriores), o pixel é considerado objeto, caso contrário, é considerado fundo.
A imagem abaixo ilustra o algoritmo de subtração descrito.

Conforme mencionado anteriormente, existem diversos algoritmos de subtração de fundo, cada um com conceitos e teorias próprios. Embora não tenha
sido foco desse trabalho, o modelo W4 de subtração de fundo utiliza alguns conceitos interessantes que foram mesclados ao algoritmo do ângulo entre
os vetores para gerar os resultados da parte de implementação desse trabalho. As seguintes adaptações foram efetuadas:
Na parte de treinamento, além da imagem média, foram armazenados 3 valores a mais por pixel para serem usados na etapa de subtração:
maior valor do mesmo pixel entre cada uma das imagens de entrada, menor valor do mesmo pixel entre cada uma das imagens de entrada
e maior diferença de valor dos pixels entre frames consecutivos.
Na parte de subtração, é realizado um processo de threshold ANTES do algoritmo descrito acima (para determinar um primeiro nível de classificação de
objetos na cena). Esse threshold é baseado nas seguintes regras: se o módulo da diferença do pixel do frame atual pelo menor valor (ou maior) do pixel
na fase de treinamento for maior que a maior diferença, esse pixel é considerado um candidato a ser objeto. As imagens abaixo ilustram tais
equações:
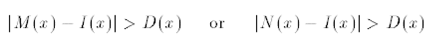
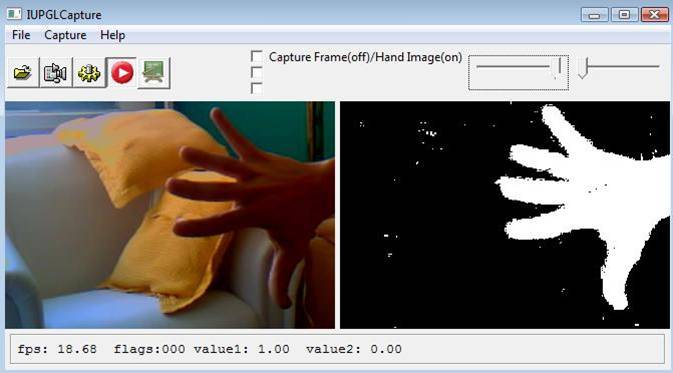
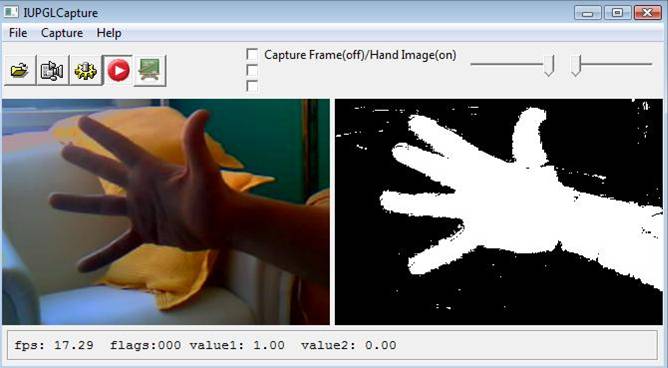
Abaixo são exibidas algumas imagens como exemplo de resultado do uso da técnica. Tais resultados foram obtidos através de uma implementação própria
com base no algoritmo híbrido (com o W4).
2.2.3 Construção de Codebooks
O algoritmo de codebooks baseia-se numa representação de cada pixel de treinamento através de um codebook cada um contendo várias codewords.
Essas codewords agrupam um conjunto de dados, os quais são representativos para identificar os pixels do fundo. Dentro desse conjunto de dados
encontram-se a distorção de cor e região de brilho do pixel. A imagem abaixo ilustra no espaço a representação de um codeword.
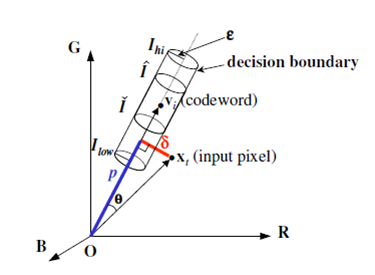
Assim com os outros dois algoritmos, o algoritmo de construção de codebooks é dividido em duas partes:
A primeira parte é realizada como pré-processamento para gerar o codebook de cada pixel. Cada codeword dos codebooks contém as seguintes informações:
(R,G,B), limiar superior e inferior de brilho, frequência, maior período no treinamento no qual esse codeword não apareceu, primeiro e último acesso.
A segunda parte é realizada frame a frame e tem como objetivo classificar os pixels do frame atual e identificar os objetos existentes (através do uso dos
codebooks e seus codewords obtidos na fase de treinamento).
O treinamento é baseado nas seguintes etapas:
1 - Captura de um número de imagens de treino.
2 - Para cada pixel de cada imagem de treino é verificado se existe um codeword representativo daquele pixel. Tal verificação é feita através da distorção
de cor e região de brilho do codeword em relação ao pixel.
3 - Caso haja, esse codeword é atualizado. Caso contrário, um novo codeword é criado.
Ao final do processo, cada pixel possui um codebook com um conjunto de codewords que representam aquele fundo. A imagem abaixo ilustra o algoritmo:

- Segmentação - Processo de Subtração
O algoritmo de subtração consiste nas seguintes etapas:
1 - Verifica-se se existe algum codeword no qual o pixel do frame que contém o objeto pode ser representado (para seu codebook).
2 - Caso exista, o pixel é classificado como fundo, caso não, como objeto.
A imagem abaixo ilustra o algoritmo de subtração descrito.

Abaixo são exibidas algumas imagens como exemplo de resultado do uso da técnica.





3 - Análise dos Algoritmos
3.1 Vantagens
- Distorção de Cor e Brilho: consegue lidar com variações de iluminação.
- Ângulo entre os Vetores de Cor: Simples, fácil implementação e rápido.
- Construção de Codebook: consegue lidar com variações de iluminação, adaptativo, fundo não precisa ser estático.
3.2 Desvantagens
- Distorção de Cor e Brilho: longo processo de treinamento.
- Ângulo entre os Vetores de Cor: não leva em consideração variações da iluminação (muito focado na cromaticidade).
- Construção de Codebook: longo processo de treinamento, implementação não trivial.
- Todos: difícil encontrar os valores corretos dos limiares.
4 - Resultados da Implementação
Nesse trabalho foi implementada a técnica do Ângulo entre os Vetores de Cor Híbrido. Para isso foi desenvolvida uma aplicação em C no Microsoft Visual
Studio 2008. Também foi utilizada a API da IM para facilitar o acesso à imagens e vídeos. Os resultados obtidos com essa aplicação encontram-se na parte
de exemplos da seção 2.2.2.
5 - Conclusões e Dificuldades Encontradas
Nesse trabalho foram apresentadas algumas técnicas para subtração de fundo, os resultados obtidos com a implementação da técnica dos Ângulos entre os
Vetores de Cor e os resultados obtidos com um código de exemplo do OpenCV para a técnica do Codebook (disponíveis na apresentação).
Embora na teoria os algoritmos não sejam de complexidade muito elevada, a implementação desses é complicada pois várias vezes é difícil encontrar
valores de limiares que se adéqüem perfeitamente aos algoritmos, além de problemas de performance.
Adicionalmente, as webcams utilizadas como base para a implementação do algoritmo possuíam muito ruído, além do ajuste automático de foco e luz, o que
dificultava a verificação e validação do código.
6 - Referências
[1] -
http://www.tecgraf.puc-rio.br/~mgattass/michel/dissertacao.pdf
[2] - Background Modeling and Subtraction by Codebook Construction, Kyungnam Kim, Thanarat H. Chalidabhongse, David Harwood, Larry Davis
[3] - Notas de aula
[4] - A Robust Background Subtraction and Shadow Detection, Thanarat H. Chalidabhongse, David Harwood, Larry Davis
[5] - W4: Who? When? Where? What? A Real Time System for Detecting and Tracking People, Ismail Haritaoglu, David Harwood, Larry Davis
[6] - Learning OpenCV: Computer Vision with OpenCV Library, Gary Bradski, Adrian Kaebler. OReilly, 2008.